Erstellen von Netzwerkabfragen mit JavaScript
Eine weitere sehr häufige Aufgabe auf modernen Websites und in Anwendungen ist das Erstellen von Netzwerkabfragen, um einzelne Datenobjekte vom Server abzurufen und so Abschnitte einer Webseite aktualisieren zu können, ohne eine komplett neue Seite laden zu müssen. Dieses scheinbar kleine Detail hat einen großen Einfluss auf die Leistung und das Verhalten von Webseiten. In diesem Artikel erklären wir das Konzept und betrachten Technologien, die dies ermöglichen, insbesondere die Fetch API.
| Voraussetzungen: | Ein Verständnis von HTML und den Grundlagen von CSS, Vertrautheit mit den Grundlagen von JavaScript, wie in den vorherigen Lektionen behandelt. |
|---|---|
| Lernziele: |
|
Was ist das Problem hier?
Eine Webseite besteht aus einer HTML-Seite und (in der Regel) verschiedenen anderen Dateien wie Stylesheets, Skripten und Bildern. Das grundlegende Modell des Seitenladens im Web besteht darin, dass Ihr Browser eine oder mehrere HTTP-Anfragen an den Server für die zum Anzeigen der Seite benötigten Dateien sendet, und der Server mit den angeforderten Dateien antwortet. Wenn Sie eine andere Seite besuchen, fordert der Browser die neuen Dateien an, und der Server antwortet mit ihnen.

Dieses Modell funktioniert für viele Seiten einwandfrei. Aber betrachten Sie eine Website, die sehr datengetrieben ist. Zum Beispiel eine Bibliothekswebsite wie die Vancouver Public Library. Unter anderem könnte man eine solche Seite als Benutzeroberfläche für eine Datenbank betrachten. Sie könnte es Ihnen ermöglichen, nach einem bestimmten Buchgenre zu suchen oder eine Empfehlung für Bücher zu erhalten, die Ihnen gefallen könnten, basierend auf Büchern, die Sie zuvor ausgeliehen haben. Wenn Sie dies tun, muss die Seite mit dem neuen Satz anzuzeigender Bücher aktualisiert werden. Beachten Sie jedoch, dass der Großteil des Seiteninhalts, einschließlich Elemente wie Seitenkopf, Seitenleiste und Fußzeile, gleich bleibt.
Das Problem beim traditionellen Modell besteht hier darin, dass wir die gesamte Seite abrufen und laden müssten, selbst wenn wir nur einen Teil davon aktualisieren müssen. Dies ist ineffizient und kann zu einem schlechten Benutzererlebnis führen.
Stattdessen verwenden viele Websites JavaScript-APIs, um Daten vom Server anzufordern und den Seiteninhalt ohne Seitenladung zu aktualisieren. So fordert der Browser, wenn der Benutzer nach einem neuen Produkt sucht, nur die Daten an, die zur Aktualisierung der Seite benötigt werden — beispielsweise den neuen Satz anzuzeigender Bücher.

Die Haupt-API hier ist die Fetch API. Diese ermöglicht es JavaScript, das in einer Seite ausgeführt wird, eine HTTP-Anfrage an einen Server zu stellen, um bestimmte Ressourcen abzurufen. Wenn der Server diese bereitstellt, kann das JavaScript die Daten verwenden, um die Seite zu aktualisieren, typischerweise durch Verwendung von DOM-Manipulations-APIs. Die angeforderten Daten sind oft JSON, welches ein gutes Format für den Transfer von strukturierten Daten ist, können aber auch HTML oder nur Text sein.
Dies ist ein übliches Muster für datengetriebene Seiten wie Amazon, YouTube, eBay und so weiter. Mit diesem Modell:
- Seitenausführungen sind viel schneller und Sie müssen nicht darauf warten, dass die Seite neu geladen wird, was bedeutet, dass sich die Seite schneller und reaktiver anfühlt.
- Weniger Daten werden bei jedem Update heruntergeladen, was weniger verschwendete Bandbreite bedeutet. Dies mag auf einem Desktop mit Breitbandverbindung kein großes Thema sein, aber es ist ein großes Thema auf mobilen Geräten und in Ländern, die keinen allgegenwärtigen schnellen Internetdienst haben.
Hinweis: In den frühen Tagen war diese generelle Technik als Asynchrones JavaScript und XML (AJAX) bekannt, da es dazu neigte, XML-Daten anzufordern. Dies ist heutzutage normalerweise nicht der Fall (Sie würden eher JSON anfordern), aber das Ergebnis ist immer noch dasselbe, und der Begriff „AJAX“ wird oft verwendet, um die Technik zu beschreiben.
Um die Geschwindigkeit noch weiter zu erhöhen, speichern einige Websites auch Ressourcen und Daten auf dem Computer des Benutzers, wenn sie das erste Mal angefordert werden, was bedeutet, dass bei späteren Besuchen die lokalen Versionen verwendet werden, anstatt jedes Mal, wenn die Seite zuerst geladen wird, neue Kopien herunterzuladen. Der Inhalt wird nur dann vom Server neu geladen, wenn er aktualisiert wurde.
Die Fetch API
In diesem Abschnitt werden wir ein paar Beispiele der Fetch API durchgehen.
Die nachfolgenden Beispiele haben einen gewissen Komplexitätsgrad und zeigen, wie die Fetch API in einigen realen Kontexten verwendet wird. Wenn Sie fetch noch nie verwendet haben, möchten Sie möglicherweise erst Scrimba's Erster Fetch MDN-Lernpartner interaktives Tutorial durcharbeiten, das einen sehr einfachen Einstieg bietet.
Abrufen von Textinhalten
Für dieses Beispiel werden wir Daten aus einigen verschiedenen Textdateien anfordern und verwenden diese, um einen Inhaltsbereich zu füllen.
Diese Datei-Serie wird als unsere simulierte Datenbank fungieren; in einer echten Anwendung würden wir eher eine serverseitige Sprache wie PHP, Python oder Node verwenden, um unsere Daten aus einer Datenbank anzufordern. Hier jedoch möchten wir es einfach halten und uns auf den clientseitigen Teil konzentrieren.
Um dieses Beispiel zu beginnen, machen Sie eine lokale Kopie von fetch-start.html und den vier Textdateien — verse1.txt, verse2.txt, verse3.txt, und verse4.txt — in einem neuen Verzeichnis auf Ihrem Computer. In diesem Beispiel werden wir einen anderen Vers des Gedichts abrufen (den Sie möglicherweise wiedererkennen), wenn er im Dropdown-Menü ausgewählt ist.
Fügen Sie direkt im <script>-Element folgenden Code hinzu. Dieser speichert Verweise auf die <select>- und <pre>-Elemente und fügt dem <select>-Element einen Listener hinzu, sodass, wenn der Benutzer einen neuen Wert auswählt, der neue Wert als Parameter an die Funktion updateDisplay() übergeben wird.
const verseChoose = document.querySelector("select");
const poemDisplay = document.querySelector("pre");
verseChoose.addEventListener("change", () => {
const verse = verseChoose.value;
updateDisplay(verse);
});
Definieren wir nun unsere updateDisplay()-Funktion. Fügen Sie zuerst das folgende Gerüst unter Ihren vorherigen Codeblock — dies ist die leere Hülle der Funktion.
function updateDisplay(verse) {
}
Wir beginnen unsere Funktion, indem wir eine relative URL konstruieren, die auf die Textdatei zeigt, die wir laden möchten, da wir sie später brauchen werden. Der Wert des <select>-Elements zu jeder Zeit ist derselbe wie der Text innerhalb des ausgewählten <option> (sofern Sie nicht einen anderen Wert in einem Wertattribut angeben) — zum Beispiel "Vers 1". Die entsprechende Strophen-Textdatei ist "verse1.txt" und befindet sich im selben Verzeichnis wie die HTML-Datei, daher wird nur der Dateiname genügen.
Webserver sind jedoch tendenziell case-sensitiv, und der Dateiname enthält keinen Leerraum. Um „Vers 1“ in „verse1.txt“ zu konvertieren, müssen wir das 'V' in Kleinbuchstaben umwandeln, den Leerraum entfernen und ".txt" am Ende hinzufügen. Dies kann mit replace(), toLowerCase(), und Template-Literale durchgeführt werden. Fügen Sie die folgenden Zeilen in Ihre updateDisplay()-Funktion ein:
verse = verse.replace(" ", "").toLowerCase();
const url = `${verse}.txt`;
Endlich sind wir bereit, die Fetch API zu verwenden:
// Call `fetch()`, passing in the URL.
fetch(url)
// fetch() returns a promise. When we have received a response from the server,
// the promise's `then()` handler is called with the response.
.then((response) => {
// Our handler throws an error if the request did not succeed.
if (!response.ok) {
throw new Error(`HTTP error: ${response.status}`);
}
// Otherwise (if the response succeeded), our handler fetches the response
// as text by calling response.text(), and immediately returns the promise
// returned by `response.text()`.
return response.text();
})
// When response.text() has succeeded, the `then()` handler is called with
// the text, and we copy it into the `poemDisplay` box.
.then((text) => {
poemDisplay.textContent = text;
})
// Catch any errors that might happen, and display a message
// in the `poemDisplay` box.
.catch((error) => {
poemDisplay.textContent = `Could not fetch verse: ${error}`;
});
Es gibt hier einiges zu beachten.
Zuerst der Einstiegspunkt zur Fetch API: eine globale Funktion namens fetch(), die die URL als Parameter nimmt (sie hat einen weiteren optionalen Parameter für benutzerdefinierte Einstellungen, aber wir verwenden diesen hier nicht).
Als nächstes ist fetch() eine asynchrone API, die ein Promise zurückgibt. Wenn Sie nicht wissen, was das ist, lesen Sie das Modul über asynchrones JavaScript und insbesondere die Lektion über Promises, dann kommen Sie hierher zurück. Sie werden feststellen, dass dieser Artikel auch über die fetch()-API spricht!
Da fetch() ein Promise zurückgibt, geben wir eine Funktion in die then()-Methode des zurückgegebenen Promises ein. Diese Methode wird aufgerufen, wenn die HTTP-Anfrage eine Antwort vom Server erhalten hat. Im Handler überprüfen wir, ob die Anfrage erfolgreich war, und werfen einen Fehler, wenn nicht. Andernfalls rufen wir response.text() auf, um den Antwortkörper als Text zu erhalten.
Es stellt sich heraus, dass response.text() auch asynchron ist, daher geben wir das von ihm zurückgegebene Promise zurück und übergeben eine Funktion in die then()-Methode dieses neuen Promises. Diese Funktion wird aufgerufen, wenn der Antworttext bereit ist, und innerhalb dieser Funktion werden wir unseren <pre>-Block mit dem Text aktualisieren.
Schließlich verketten wir einen catch()-Handler an das Ende, um Fehler abzufangen, die in einer der aufgerufenen asynchronen Funktionen oder deren Handler ausgelöst werden.
Ein Problem mit dem Beispiel, wie es steht, ist, dass es keinen der Verse anzeigt, wenn es zuerst geladen wird. Um dies zu beheben, fügen Sie die folgende zwei Zeilen am Ende Ihres Codes (direkt über dem schließenden </script>-Tag) hinzu, um standardmäßig den ersten Vers zu laden, und stellen Sie sicher, dass das <select>-Element immer den richtigen Wert anzeigt:
updateDisplay("Verse 1");
verseChoose.value = "Verse 1";
Ihr Beispiel von einem Server aus bereitstellen
Moderne Browser werden keine HTTP-Anfragen ausführen, wenn Sie das Beispiel lediglich von einer lokalen Datei aus starten. Dies liegt an Sicherheitsbeschränkungen (weitere Informationen zur Websicherheit finden Sie unter Website-Sicherheit).
Um dies zu umgehen, müssen wir das Beispiel testen, indem wir es über einen lokalen Webserver ausführen. Wie dies gemacht wird, erfahren Sie unter Wie richtet man einen lokalen Testserver ein?.
The Can Store
In diesem Beispiel haben wir eine Beispielseite namens The Can Store erstellt — es handelt sich um einen fiktiven Supermarkt, der nur Dosenwaren verkauft. Sie können dieses [Beispiel live auf GitHub] (https://mdn.github.io/learning-area/javascript/apis/fetching-data/can-store/) sehen und die Sourcecodes ansehen.
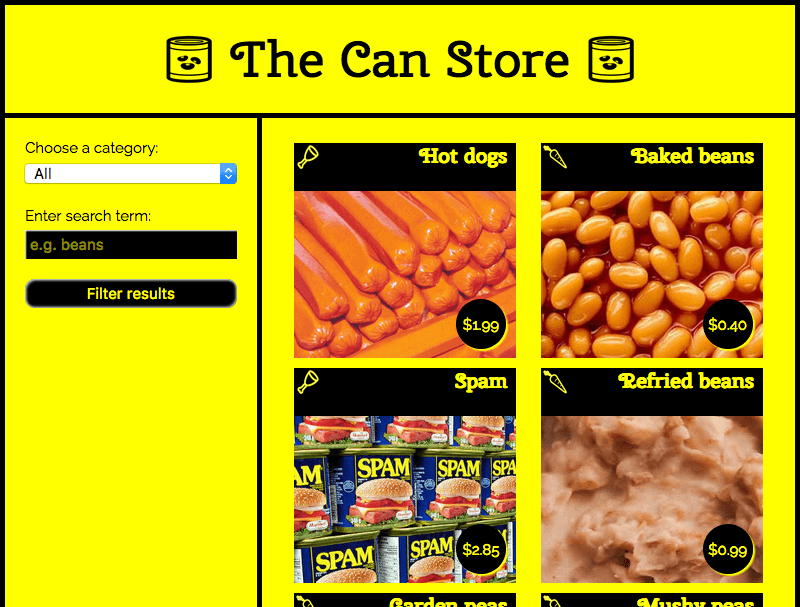
Standardmäßig zeigt die Seite alle Produkte an, aber Sie können die Suchsteuerungen in der linken Spalte verwenden, um sie nach Kategorie oder Suchbegriff oder beides zu filtern.
Es gibt ziemlich viel komplexen Code, der sich mit dem Filtern der Produkte nach Kategorie und Suchbegriffen befasst, Zeichenketten manipuliert, sodass die Daten korrekt in der Benutzeroberfläche angezeigt werden, usw. Wir werden nicht alles im Artikel diskutieren, aber Sie können umfassende Kommentare im Code finden (siehe can-script.js).
Wir werden jedoch den Fetch-Code erklären.
Der erste Block, der Fetch verwendet, kann am Anfang des JavaScript gefunden werden:
fetch("products.json")
.then((response) => {
if (!response.ok) {
throw new Error(`HTTP error: ${response.status}`);
}
return response.json();
})
.then((json) => initialize(json))
.catch((err) => console.error(`Fetch problem: ${err.message}`));
Die fetch()-Funktion gibt ein Promise zurück. Wenn dieses erfolgreich abgeschlossen wird, enthält die Funktion im ersten .then()-Block die response, die vom Netzwerk zurückgegeben wird.
Innerhalb dieser Funktion:
- überprüfen wir, ob der Server keinen Fehler zurückgegeben hat (wie
404 Not Found). Wenn dies der Fall ist, werfen wir den Fehler. - rufen
json()auf der Antwort auf. Dies wird die Daten als JSON-Objekt abrufen. Wir geben das zurückgegebene Promise vonresponse.json()zurück.
Als nächstes geben wir eine Funktion in die then()-Methode dieses zurückgegebenen Promises ein. Diese Funktion wird ein Objekt enthalten, das die Antwortdaten als JSON enthält, das wir in die initialize()-Funktion übergeben. Es ist initialize(), das den Prozess des Anzeigens aller Produkte in der Benutzeroberfläche startet.
Um Fehler zu behandeln, fügen wir einen .catch()-Block an das Ende der Kette an. Dieser wird ausgeführt, wenn das Promise aus irgendeinem Grund fehlschlägt. Wir fügen darin eine Funktion ein, die als Parameter ein err-Objekt übermittelt bekommt. Dieses err-Objekt kann verwendet werden, um die Art des aufgetretenen Fehlers zu melden; wir tun dies mit einem einfachen console.error().
Ein vollständige Webseite würde diesen Fehler jedoch eleganter behandeln, indem sie eine Nachricht auf dem Bildschirm des Benutzers anzeigt und möglicherweise Optionen bietet, um die Situation zu beheben, aber wir benötigen nichts weiter als ein einfaches console.error().
Sie können den Fehlerfall selbst testen:
- Erstellen Sie eine lokale Kopie der Beispieldateien.
- Führen Sie den Code über einen Webserver aus (wie oben beschrieben, unter Ihr Beispiel von einem Server aus bereitstellen).
- Ändern Sie den Pfad zur Datei, die abgerufen wird, in etwas wie 'produc.json' (stellen Sie sicher, dass es falsch geschrieben ist).
- Laden Sie nun die Indexdatei in Ihrem Browser (über
localhost:8000) und schauen Sie in die Entwicklerkonsole Ihres Browsers. Sie werden eine Nachricht ähnlich wie "Fetch-Problem: HTTP-Fehler: 404" sehen.
Der zweite Fetch-Block kann in der fetchBlob()-Funktion gefunden werden:
fetch(url)
.then((response) => {
if (!response.ok) {
throw new Error(`HTTP error: ${response.status}`);
}
return response.blob();
})
.then((blob) => showProduct(blob, product))
.catch((err) => console.error(`Fetch problem: ${err.message}`));
Dies funktioniert ähnlich wie der vorherige, außer dass wir anstelle von json() blob() verwenden. In diesem Fall möchten wir unsere Antwort als Bilddatei zurückgeben, und das Datenformat, das wir dafür verwenden, ist Blob (der Begriff ist eine Abkürzung für "Binary Large Object" und kann im Wesentlichen verwendet werden, um große dateiähnliche Objekte wie Bilder oder Videodateien darzustellen).
Sobald wir unser Blob erfolgreich erhalten haben, geben wir es in unsere showProduct()-Funktion ein, die es anzeigt.
Die XMLHttpRequest API
Manchmal, vor allem in älterem Code, werden Sie eine andere API namens XMLHttpRequest (oft abgekürzt als "XHR") sehen, die verwendet wird, um HTTP-Anfragen zu erstellen. Diese ist älter als Fetch und war wirklich die erste API, die weit verbreitet war, um AJAX zu implementieren. Wir empfehlen, wenn möglich, Fetch zu verwenden: es ist eine einfachere API und hat mehr Funktionen als XMLHttpRequest. Wir werden keinen Beispielbeitrag durchgehen, der XMLHttpRequest verwendet, aber wir zeigen Ihnen, wie die XMLHttpRequest-Version unserer ersten Can-Store-Anfrage aussehen würde:
const request = new XMLHttpRequest();
try {
request.open("GET", "products.json");
request.responseType = "json";
request.addEventListener("load", () => initialize(request.response));
request.addEventListener("error", () => console.error("XHR error"));
request.send();
} catch (error) {
console.error(`XHR error ${request.status}`);
}
Es gibt fünf Phasen hierzu:
- Erstellen Sie ein neues
XMLHttpRequest-Objekt. - Rufen Sie seine
open()-Methode auf, um es zu initialisieren. - Fügen Sie einen Event-Listener für sein
load-Ereignis hinzu, das ausgelöst wird, wenn die Antwort erfolgreich abgeschlossen ist. Im Listener rufen wirinitialize()mit den Daten auf. - Fügen Sie einen Event-Listener für sein
error-Ereignis hinzu, das ausgelöst wird, wenn die Anfrage einen Fehler trifft - Senden Sie die Anfrage.
Wir müssen auch das Ganze im try...catch-Block einschließen, um alle vom open() oder send() geworfenen Fehler zu handhaben.
Hoffentlich denken Sie, dass die Fetch API gegenüber dieser eine Verbesserung darstellt. Insbesondere sehen Sie, wie wir Fehler an zwei verschiedenen Stellen behandeln müssen.
Zusammenfassung
Dieser Artikel zeigt, wie man beginnt, mit Fetch zu arbeiten, um Daten vom Server abzurufen.
Siehe auch
Es gibt jedoch viele verschiedene Themen, die in diesem Artikel besprochen werden, der nur wirklich an der Oberfläche gekratzt hat. Für viel mehr Detail zu diesen Themen versuchen Sie die folgenden Artikel: