Verwendung der Web Speech API
Die Web Speech API bietet zwei verschiedene Funktionsbereiche – Spracherkennung und Sprachsynthese (auch bekannt als Text-to-Speech oder TTS) – die interessante Möglichkeiten für Barrierefreiheit und Steuerung eröffnen. Dieser Artikel bietet eine Einführung in beide Bereiche, zusammen mit Demos.
Spracherkennung
Die Spracherkennung beinhaltet das Empfangen von Audio von einem Mikrofon des Geräts (oder von einer Audiospur), das dann von einem Spracherkennungsdienst überprüft wird. Wenn der Dienst ein Wort oder einen Satz erfolgreich erkennt, gibt er eine Textzeichenkette (oder eine Liste von Zeichenketten) zurück, die Sie verwenden können, um weitere Aktionen einzuleiten.
Die Web Speech API hat eine Hauptschnittstelle für die Steuerung – SpeechRecognition – und mehrere verwandte Schnittstellen zur Darstellung der Ergebnisse.
In der Regel wird das auf dem Gerät des Benutzers verfügbare Spracherkennungssystem für die Spracherkennung verwendet. Die meisten modernen Betriebssysteme verfügen über ein Spracherkennungssystem zur Erteilung von Sprachbefehlen, wie Diktat auf macOS oder Copilot auf Windows.
Standardmäßig beinhaltet die Verwendung der Spracherkennung auf einer Webseite eine serverbasierte Erkennungsmaschine. Ihr Audio wird zu einem Webdienst zur Erkennungsverarbeitung gesendet, daher funktioniert es nicht offline.
Um die Privatsphäre und Leistung zu verbessern, können Sie angeben, dass die Spracherkennung auf dem Gerät durchgeführt wird. Dies stellt sicher, dass weder das Audio noch die transkribierte Sprache zur Verarbeitung an einen Drittanbieterdienst gesendet werden. Wir behandeln die Funktionalität auf dem Gerät ausführlicher im Abschnitt Spracherkennung auf dem Gerät.
Demo
Um zu demonstrieren, wie man Spracherkennung verwendet, haben wir eine Beispiel-App namens Speech Color Changer erstellt. Nachdem Sie die Schaltfläche Start recognition gedrückt haben, sagen Sie ein HTML-Farbkeyword. Die Hintergrundfarbe der App ändert sich in diese Farbe.

Um die Demo auszuführen, navigieren Sie zur Live-Demo-URL in einem unterstützenden Browser.
HTML und CSS
Das HTML und CSS für die App sind einfach. Es gibt einen Titel, einen Anweisungsabsatz (<p>), ein Steuerungs-<button> und einen Ausgabeabsatz, in dem wir Diagnosemeldungen anzeigen, einschließlich der Wörter, die unsere App erkannt hat.
<h1>Speech color changer</h1>
<p class="hints"></p>
<button>Start recognition</button>
<p class="output"><em>...diagnostic messages</em></p>
Das CSS bietet ein grundlegendes responsives Styling, so dass es auf verschiedenen Geräten gut aussieht.
JavaScript
Schauen wir uns das JavaScript etwas genauer an.
Präfixierte Eigenschaften
Einige Browser unterstützen derzeit die Spracherkennung mit präfixierten Eigenschaften. Daher enthalten wir am Anfang unseres Codes diese Zeilen, um sowohl präfixierte als auch unpräfixierte Versionen zu erlauben:
const SpeechRecognition =
window.SpeechRecognition || window.webkitSpeechRecognition;
const SpeechRecognitionEvent =
window.SpeechRecognitionEvent || window.webkitSpeechRecognitionEvent;
Farbliste
Der nächste Teil unseres Codes definiert einige Beispiel-Farben, die wir der Benutzeroberfläche anzeigen, um den Benutzern eine Vorstellung davon zu geben, was sie sagen sollen:
const colors = [
"aqua",
"azure",
"beige",
"bisque",
"black",
"blue",
"brown",
"chocolate",
"coral",
// …
];
Erstellung einer Spracherkennung-Instanz
Als nächstes definieren wir eine Spracherkennung-Instanz, um die Erkennung in unserer App zu steuern. Dies tun wir mit dem SpeechRecognition()-Konstruktor.
const recognition = new SpeechRecognition();
Dann setzen wir einige Eigenschaften der Erkennungsinstanz:
SpeechRecognition.continuous: Bestimmt, ob die Ergebnisse kontinuierlich (true) oder nur einmal bei jedem Start einer Erkennung erfasst werden (false).SpeechRecognition.lang: Setzt die Sprache der Erkennung. Dies explizit festzulegen, ist die empfohlene beste Praxis.SpeechRecognition.interimResults: Definiert, ob das Spracherkennungssystem vorläufige Ergebnisse oder nur endgültige Ergebnisse zurückgeben soll. Für diese Demo sind endgültige Ergebnisse ausreichend.SpeechRecognition.maxAlternatives: Setzt die Anzahl alternativer potenzieller Treffer, die pro Ergebnis zurückgegeben werden sollen. Dies kann manchmal nützlich sein, beispielsweise wenn ein Ergebnis nicht völlig klar ist und Sie eine Liste von Alternativen anzeigen möchten, aus denen der Benutzer wählen kann. Aber für diese Demo ist es nicht erforderlich, also geben wir nur eine an (was sowieso der Standard ist).
recognition.continuous = false;
recognition.lang = "en-US";
recognition.interimResults = false;
recognition.maxAlternatives = 1;
Start der Spracherkennung
Nachdem wir Referenzen zum Ausgabeabsatz, dem <html>-Element, dem Anweisungsabsatz und dem <button> erfasst haben, implementieren wir einen onclick-Handler. Wenn ein Benutzer die Schaltfläche drückt, startet der Spracherkennungsdienst, indem SpeechRecognition.start() aufgerufen wird. Wir haben auch eine forEach()-Methode verwendet, um farbige Indikatoren auszugeben, die anzeigen, welche Farben Benutzer versuchen können zu sagen.
const diagnostic = document.querySelector(".output");
const bg = document.querySelector("html");
const hints = document.querySelector(".hints");
const startBtn = document.querySelector("button");
const colorHTML = colors
.map((v) => `<span style="background-color:${v};">${v}</span>`)
.join("");
hints.innerHTML = `Press the button then say a color to change the background color of the app. Try ${colorHTML}.`;
startBtn.onclick = () => {
recognition.start();
console.log("Ready to receive a color command.");
};
Empfang und Verarbeitung von Ergebnissen
Sobald die Spracherkennung gestartet wurde, stehen mehrere Ereignis-Handler zur Verfügung, die verwendet werden können, um Ergebnisse und andere verwandte Informationen abzurufen (siehe Ereignisse für SpeechRecognition). Der am häufigsten verwendete ist das result-Ereignis, das nach Erhalt eines erfolgreichen Ergebnisses ausgelöst wird:
recognition.onresult = (event) => {
const color = event.results[0][0].transcript;
diagnostic.textContent = `Result received: ${color}.`;
bg.style.backgroundColor = color;
console.log(`Confidence: ${event.results[0][0].confidence}`);
};
Die zweite Zeile ist etwas komplex, daher erklären wir hier jeden Teil:
- Die
SpeechRecognitionEvent.results-Eigenschaft gibt einSpeechRecognitionResultList-Objekt zurück, dasSpeechRecognitionResult-Objekte enthält. Es hat einen Getter, sodass es wie ein Array zugegriffen werden kann – das erste[0]gibt dasSpeechRecognitionResultan Position0zurück. - Jedes
SpeechRecognitionResult-Objekt enthält wiederumSpeechRecognitionAlternative-Objekte, die jeweils ein erkanntes Wort darstellen. Diese haben auch Getter, sodass sie wie Arrays zugegriffen werden können – das zweite[0]gibt dieSpeechRecognitionAlternativean Position0zurück. - Die
transcript-Eigenschaft derSpeechRecognitionAlternativegibt eine Zeichenkette zurück, die den erkannten Text enthält. Dieser Wert wird dann verwendet, um die Hintergrundfarbe in eine erkannte Farbe zu ändern und auch als Diagnosemeldung in der Benutzeroberfläche zu melden.
Wir verwenden auch das speechend-Ereignis, um den Spracherkennungsdienst zu stoppen (mit SpeechRecognition.stop()), nachdem ein einzelnes Wort erkannt wurde:
recognition.onspeechend = () => {
recognition.stop();
};
Umgang mit Fehlern und nicht erkannten Wörtern
Die letzten beiden Handler behandeln Fälle, in denen der gesprochene Begriff nicht erkannt wird oder ein Fehler bei der Erkennung auftritt. Das nomatch-Ereignis soll den ersten Fall behandeln, obwohl das Erkennungs-Engine in den meisten Fällen etwas zurückgibt, selbst wenn es unverständlich ist:
recognition.onnomatch = (event) => {
diagnostic.textContent = "I didn't recognize that color.";
};
Das error-Ereignis behandelt Fälle, in denen ein tatsächlicher Fehler bei der Erkennung vorliegt – die SpeechRecognitionErrorEvent.error-Eigenschaft enthält den zurückgegebenen Fehler:
recognition.onerror = (event) => {
diagnostic.textContent = `Error occurred in recognition: ${event.error}`;
};
Spracherkennung auf dem Gerät
Die Spracherkennung wird normalerweise mit einem Online-Dienst durchgeführt. Das bedeutet, dass eine Audioaufnahme an einen Server zur Verarbeitung gesendet wird und die Ergebnisse dann an den Browser zurückgegeben werden. Dies hat einige Probleme:
- Privatsphäre: Viele Benutzer sind nicht damit einverstanden, dass ihre Sprache an einen Server gesendet wird.
- Leistung: Das Senden von Daten an einen Server für jede Erkennung kann die Leistung in intensiveren Anwendungen verlangsamen und Ihre Apps funktionieren nicht offline.
Um diese Probleme zu mindern, lässt die Web Speech API Sie angeben, dass die Spracherkennung vom Browser auf dem Gerät gehandhabt werden soll. Dies erfordert einen einmaligen Sprachpaket-Download für jede Sprache, die Sie erkennen möchten; einmal installiert, wird die Funktionalität offline verfügbar sein.
Dieser Abschnitt erklärt, wie man die Spracherkennung auf dem Gerät verwendet.
Demo
Um die Spracherkennung auf dem Gerät zu demonstrieren, haben wir eine Beispiel-App namens On-device Speech Color Changer erstellt (Demo live ausführen).
Diese Demo funktioniert sehr ähnlich zur bereits besprochenen Online-Variante der Speech Colour Changer Demo, mit den unten angegebenen Unterschieden.
Hinweis: In der ursprünglichen Speech Color Changer Demo haben wir zusätzliche Zeilen hinzugefügt, um Browser zu behandeln, die die Web Speech API nur mit anbieterpräfixierten Eigenschaften unterstützen (siehe den Abschnitt Präfixierte Eigenschaften für weitere Details). In der On-Device-Version der Demo ist kein Präfixierungs-Code erforderlich, da die Implementierungen, die diese Funktionalität unterstützen, dies ohne Präfixe tun.
Spezifizieren der On-Device-Erkennung
Um anzugeben, dass Sie die Verarbeitung auf dem Gerät durch den Browser verwenden möchten, setzen Sie die SpeechRecognition.processLocally-Eigenschaft vor dem Starten einer Spracherkennung auf true (der Standardwert ist false):
recognition.processLocally = true;
Verfügbarkeit prüfen und Sprachpakete installieren
Damit die Spracherkennung auf dem Gerät funktioniert, muss der Browser über ein installiertes Sprachpaket für die Sprache verfügen, die Sie erkennen möchten. Wenn Sie die start()-Methode ausführen, nachdem Sie processLocally = true angegeben haben, das richtige Sprachpaket jedoch nicht installiert ist, schlägt der Funktionsaufruf mit einem language-not-supported-Fehler fehl.
Um sicherzustellen, dass das richtige Sprachpaket installiert wird, befolgen Sie diese zwei Schritte:
- Prüfen Sie, ob das Sprachpaket auf dem Gerät des Benutzers verfügbar ist: Dies wird mit der statischen Methode
SpeechRecognition.available()gehandhabt. - Installieren Sie das Sprachpaket, wenn es nicht verfügbar ist: Dies wird mit der statischen Methode
SpeechRecognition.install()gehandhabt.
Diese Schritte werden im folgenden click-Ereignis-Handler auf dem Steuerungs-<button> der App gehandhabt:
startBtn.addEventListener("click", () => {
// check availability of target language
SpeechRecognition.available({ langs: ["en-US"], processLocally: true }).then(
(result) => {
if (result === "unavailable") {
diagnostic.textContent = `en-US is not available to download at this time. Sorry!`;
} else if (result === "available") {
recognition.start();
console.log("Ready to receive a color command.");
} else {
diagnostic.textContent = `en-US language pack is downloading...`;
SpeechRecognition.install({
langs: ["en-US"],
processLocally: true,
}).then((result) => {
if (result) {
diagnostic.textContent = `en-US language pack downloaded. Start recognition again.`;
} else {
diagnostic.textContent = `en-US language pack failed to download. Try again later.`;
}
});
}
},
);
});
Die available()-Methode nimmt ein Optionsobjekt entgegen, das zwei Eigenschaften enthält:
- Ein
langs-Array, das die Sprachen enthält, für die die Verfügbarkeit geprüft werden soll. - Ein
processLocally-Boolean, der angibt, ob die Verfügbarkeit der Sprache nur auf dem Gerät (true) oder lokal oder über einen Server-basierten Erkennungsdienst (false, die Standardeinstellung) geprüft werden soll.
Wird diese Methode ausgeführt, gibt sie ein Promise zurück, das mit einem Wert aufgelöst wird, der die Verfügbarkeit der angegebenen Sprachen angibt. In unserer Demo testen wir für drei Bedingungen:
- Wenn der zurückgegebene Wert
unavailableist, bedeutet das, dass kein geeignetes Sprachpaket zum Herunterladen verfügbar ist. Wir drucken auch eine entsprechende Nachricht an die Ausgabe. - Wenn der Wert
availableist, bedeutet das, dass das Sprachpaket lokal verfügbar ist, sodass die Erkennung beginnen kann. In diesem Fall führen wirstart()aus und loggen eine Nachricht in die Konsole, wenn die App bereit ist, Sprache zu empfangen. - Wenn der Wert etwas anderes ist (
downloadableoderdownloading), drucken wir eine Diagnosemeldung aus, um den Benutzer darüber zu informieren, dass ein Sprachpaket-Download beginnt, und führen dann dieinstall()-Methode aus, um den Download zu handhaben.
Die install()-Methode funktioniert ähnlich wie die available()-Methode, außer dass ihr Optionsobjekt nur das langs-Array enthält. Wird sie ausgeführt, startet sie das Herunterladen aller Sprachpakete für die in langs angegebenen Sprachen und gibt ein Promise zurück, das mit einem Boolean aufgelöst wird, der angibt, ob die angegebenen Sprachpakete erfolgreich heruntergeladen und installiert wurden (true) oder nicht (false).
Für diese Demo drucken wir eine Diagnosemeldung, die die Erfolgs- und Fehlermanagementfälle anzeigt. In einer vollständigeren App würden Sie wahrscheinlich die Steuerungen während des Download-Prozesses deaktivieren und sie wieder aktivieren, nachdem das Versprechen erfüllt ist.
Integration der Berechtigungsrichtlinie
Die Verwendung der Methoden available() und install() wird durch die on-device-speech-recognition-Permissions-Policy gesteuert. Speziell, wo eine definierte Richtlinie die Nutzung blockiert, wird jeder Versuch, diese Methoden aufzurufen, fehlschlagen.
Der Standardwerteintragswert für on-device-speech-recognition ist self. Das bedeutet, dass Sie sich keine Sorgen um die Anpassung der Richtlinie machen müssen, es sei denn, Sie versuchen, diese Methoden in eingebetteten Cross-Origin-Dokumenten zu verwenden oder möchten deren Verwendung explizit deaktivieren.
Festlegen von Anforderungen an die Qualitätsstufe
Die Methoden available() und install() unterstützen die quality-Option. Dies ermöglicht es Ihnen, die Unterstützung für verschiedene Komplexitätsstufen der Spracherkennung zu überprüfen – zum Beispiel ist die Verarbeitung kurzer Sprachbefehle viel einfacher als das Handhaben von Diktaten/Transkriptionen, und der erstere Anwendungsfall wird wahrscheinlich von mehr Hardware- und Sprachpaketkombinationen unterstützt als der letztere.
Zum Beispiel ist der folgende Code-Snippet eine Modifikation des Codes aus dem Beispiel On-device Speech Color Changer, in dem wir die available()-Methode mit der auf dictation gesetzten quality-Option aufrufen, um zu überprüfen, ob die Spracherkennung auf dem Gerät diese Qualitätsstufe unterstützt. Wenn das zurückgegebene Ergebnis unavailable ist, setzen wir die Eigenschaft processLocally des SpeechRecognition-Objekts auf false, um die API zu zwingen, einen Cloud-Erkennungsdienst zu verwenden, und starten dann den Erkennungsdienst.
Wenn das Ergebnis available ist, sind wir bereit, also rufen wir einfach start() auf, um die Erkennung auf dem Gerät zu starten. Wenn das Ergebnis ein anderer Wert ist, führen wir die install()-Methode mit der auf dictation gesetzten quality-Option aus, um die erforderlichen Sprachpakete zu installieren.
startBtn.addEventListener("click", () => {
// Check availability of on-device target language dictation quality
SpeechRecognition.available({
langs: ["en-US"],
processLocally: true,
quality: "dictation",
}).then((result) => {
if (result === "unavailable") {
diagnostic.textContent = `On-device recognition for dictation not available, running with cloud recognition`;
recognition.processLocally = false;
recognition.start();
} else if (result === "available") {
recognition.start();
console.log("Ready to receive a color command.");
} else {
diagnostic.textContent = `en-US language pack downloading`;
SpeechRecognition.install({
langs: ["en-US"],
processLocally: true,
quality: "dictation",
}).then((result) => {
if (result) {
diagnostic.textContent = `en-US language pack downloaded. Try again.`;
} else {
diagnostic.textContent = `en-US language pack failed to download. Try again later.`;
}
});
}
});
});
Kontextuelle Verzerrung in der Spracherkennung
Es wird Zeiten geben, in denen ein Spracherkennungsdienst es nicht schafft, ein bestimmtes Wort oder eine bestimmte Phrase korrekt zu erkennen. Dies passiert am häufigsten bei branchenspezifischen Begriffen (wie medizinischer oder wissenschaftlicher Terminologie), Eigennamen, ungewöhnlichen Phrasen oder Wörtern, die anderen Wörtern ähnlich klingen und deshalb möglicherweise falsch identifiziert werden.
Zum Beispiel haben wir während der Tests festgestellt, dass unser On-device Speech Color Changer Schwierigkeiten hatte, die Farbe azure zu erkennen – ständig wurden Ergebnisse wie "as you" zurückgegeben. Andere Farben, die häufig falsch erkannt wurden, waren khaki ("car key"), tan und thistle ("this all").
Um solche Probleme zu mildern, lässt die Web Speech API Sie dem Erkennungs-Engine Hinweise geben, um Phrasen hervorzuheben, die mit größerer Wahrscheinlichkeit gesprochen werden, und auf die die Engine verzerrt werden sollte. Dies macht es wahrscheinlicher, dass diese Wörter und Phrasen korrekt erkannt werden.
Sie können dies tun, indem Sie ein Array von SpeechRecognitionPhrase-Objekten als Wert der SpeechRecognition.phrases-Eigenschaft setzen. Jedes SpeechRecognitionPhrase-Objekt enthält:
- Eine
phrase-Eigenschaft, die eine Zeichenkette enthält, die das zu verstärkende Wort oder die zu verstärkende Phrase enthält. - Eine
boost-Eigenschaft, die eine Gleitkommazahl zwischen0.0und10.0(einschließlich) ist, die den Verstärkungsgrad angibt, den Sie auf dieses Wort oder diese Phrase anwenden möchten. Höhere Werte machen das Wort oder die Phrase wahrscheinlicher erkannt.
In unserer "On-device Speech Color Changer"-Demo handhaben wir dies, indem wir ein Array von Phrasen zur Verstärkung und deren Verstärkungswerte erstellen:
const phraseData = [
{ phrase: "azure", boost: 5.0 },
{ phrase: "khaki", boost: 3.0 },
{ phrase: "tan", boost: 2.0 },
];
Diese müssen als ein ObservableArray von SpeechRecognitionPhrase-Objekten dargestellt werden. Wir handhaben dies, indem wir das ursprüngliche Array umbilden, um jedes Array-Element mit dem SpeechRecognitionPhrase()-Konstruktor in ein SpeechRecognitionPhrase-Objekt zu konvertieren:
const phraseObjects = phraseData.map(
(p) => new SpeechRecognitionPhrase(p.phrase, p.boost),
);
Nach dem Erstellen der SpeechRecognition-Instanz fügen wir unsere kontextuellen Verzerrungsphrasen hinzu, indem wir das phraseObjects-Array als Wert der SpeechRecognition.phrases-Eigenschaft setzen:
recognition.phrases = phraseObjects;
Das Phrasen-Array kann wie ein normales JavaScript-Array modifiziert werden, zum Beispiel durch das dynamische Hinzufügen neuer Phrasen:
recognition.phrases.push(new SpeechRecognitionPhrase("thistle", 5.0));
Mit diesem Code stellten wir fest, dass die problematischen Farb-Keywords genauer erkannt wurden als zuvor.
Sprachsynthese
Die Sprachsynthese (auch bekannt als Text-to-Speech, oder TTS) beinhaltet die Synthese eines Textes, der in einer Anwendung enthalten ist, in Sprache und das Abspielen über die Lautsprecher oder den Audioausgang eines Geräts.
Die Web Speech API hat eine Hauptsteuerungsschnittstelle dafür – SpeechSynthesis – sowie eine Reihe verwandter Schnittstellen zur Darstellung des zu synthetisierenden Texts (bekannt als Äußerungen), der Stimmen, die für die Äußerung verwendet werden sollen, etc. Auch hier haben die meisten Betriebssysteme eine Art Sprachsynthesesystem, das von der API für diese Aufgabe verwendet wird, soweit vorhanden.
Demo
Um zu demonstrieren, wie man die Sprachsynthese im Web verwendet, haben wir eine Beispiel-App namens Speech Synthesizer erstellt. Sie verfügt über ein Eingabefeld zur Eingabe des zu synthetisierenden Texts. Sie können die Geschwindigkeit und die Tonhöhe anpassen und auch eine Stimme aus dem Dropdown-Menü auswählen, um den gesprochenen Text zu verwenden. Nachdem Sie Ihren Text eingegeben haben, drücken Sie Enter/Return oder klicken Sie auf die Play-Schaltfläche, um den Text laut vorlesen zu lassen.
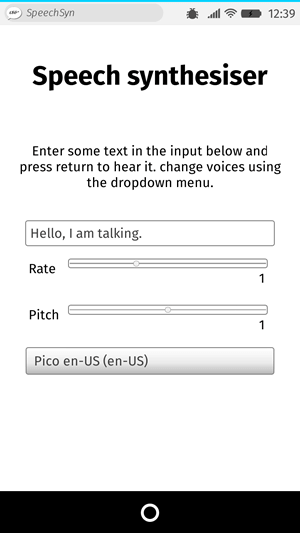
Um die Demo auszuführen, navigieren Sie zur Live-Demo-URL in einem unterstützenden Browser.
HTML und CSS
Das HTML und CSS für diese App sind ziemlich einfach. Es gibt einen Titel, einige Anweisungen zur Nutzung und ein Formular mit grundlegenden Steuerelementen. Das <select>-Element ist anfangs leer; es wird über JavaScript mit <option>s gefüllt (später behandelt).
<h1>Speech synthesizer</h1>
<p>
Enter some text in the input below and press return to hear it. Change voices
using the dropdown menu.
</p>
<form>
<input type="text" class="txt" />
<div>
<label for="rate">Rate</label
><input type="range" min="0.5" max="2" value="1" step="0.1" id="rate" />
<div class="rate-value">1</div>
<div class="clearfix"></div>
</div>
<div>
<label for="pitch">Pitch</label
><input type="range" min="0" max="2" value="1" step="0.1" id="pitch" />
<div class="pitch-value">1</div>
<div class="clearfix"></div>
</div>
<select></select>
</form>
JavaScript
Schauen wir uns das JavaScript an, das diese App antreibt.
Variablen setzen
Zunächst erfassen wir Referenzen auf alle an der Benutzeroberfläche beteiligten DOM-Elemente, aber interessanterweise erfassen wir eine Referenz auf Window.speechSynthesis. Dies ist der Einstiegspunkt der API – es gibt eine Instanz von SpeechSynthesis zurück, der Steuerungsschnittstelle für die Sprachsynthese im Web.
const synth = window.speechSynthesis;
const inputForm = document.querySelector("form");
const inputTxt = document.querySelector(".txt");
const voiceSelect = document.querySelector("select");
const pitch = document.querySelector("#pitch");
const pitchValue = document.querySelector(".pitch-value");
const rate = document.querySelector("#rate");
const rateValue = document.querySelector(".rate-value");
const voices = [];
Füllen des Select-Elements
Um das <select>-Element mit den verfügbaren Sprachoptionen des Geräts zu füllen, haben wir eine populateVoiceList()-Funktion geschrieben. Zuerst rufen wir SpeechSynthesis.getVoices() auf, das eine Liste aller verfügbaren Stimmen zurückgibt, dargestellt durch SpeechSynthesisVoice-Objekte. Dann durchlaufen wir diese Liste – für jede Stimme erstellen wir ein <option>-Element, setzen seinen Textinhalt, um den Namen der Stimme anzuzeigen (aus SpeechSynthesisVoice.name entnommen), die Sprache der Stimme (aus SpeechSynthesisVoice.lang entnommen) und -- DEFAULT, wenn die Stimme die Standardsprache für die Synthese-Engine ist (überprüft, indem man prüft, ob SpeechSynthesisVoice.default true zurückgibt.)
Wir erstellen auch data--Attribute für jede Option, die den Namen und die Sprache der zugehörigen Stimme enthalten, sodass wir sie später leicht erfassen können, und fügen die Optionen als Kinder des Select-Elements hinzu.
function populateVoiceList() {
voices = synth.getVoices();
for (const voice of voices) {
const option = document.createElement("option");
option.textContent = `${voice.name} (${voice.lang})`;
if (voice.default) {
option.textContent += " — DEFAULT";
}
option.setAttribute("data-lang", voice.lang);
option.setAttribute("data-name", voice.name);
voiceSelect.appendChild(option);
}
}
Ältere Browser unterstützen das voiceschanged-Ereignis nicht und geben einfach eine Liste der Stimmen zurück, wenn SpeechSynthesis.getVoices() ausgeführt wird. Während bei anderen, wie Chrome, Sie warten müssen, bis das Ereignis ausgelöst wird, bevor die Liste gefüllt wird. Um beide Fälle zuzulassen, führen wir die Funktion wie unten gezeigt aus:
populateVoiceList();
if (speechSynthesis.onvoiceschanged !== undefined) {
speechSynthesis.onvoiceschanged = populateVoiceList;
}
Sprechen des eingegebenen Texts
Als nächstes erstellen wir einen Ereignishandler, um das Sprechen des in das Textfeld eingegebenen Texts zu starten. Wir verwenden einen onsubmit-Handler auf dem Formular, damit die Aktion ausgeführt wird, wenn Enter/Return gedrückt wird. Zuerst erstellen wir eine neue SpeechSynthesisUtterance()-Instanz mit dessen Konstruktor. Dieser wird mit dem Wert des Texteingabefelds als Parameter übergeben.
Als nächstes müssen wir herausfinden, welche Stimme verwendet werden soll. Wir verwenden die selectedOptions-Eigenschaft von HTMLSelectElement, um das derzeit ausgewählte <option>-Element zurückzugeben. Dann verwenden wir das data-name-Attribut dieses Elements und finden das SpeechSynthesisVoice-Objekt, dessen Name mit dem Wert dieses Attributs übereinstimmt. Wir setzen das übereinstimmende Sprachobjekt als Wert für die SpeechSynthesisUtterance.voice-Eigenschaft.
Schließlich setzen wir die SpeechSynthesisUtterance.pitch und SpeechSynthesisUtterance.rate auf die Werte der entsprechenden Formular-Elemente. Dann, mit allen notwendigen Vorbereitungen, starten wir die Äußerung, indem wir SpeechSynthesis.speak() aufrufen und die SpeechSynthesisUtterance-Instanz als Parameter übergeben.
inputForm.onsubmit = (event) => {
event.preventDefault();
const utterThis = new SpeechSynthesisUtterance(inputTxt.value);
const selectedOption =
voiceSelect.selectedOptions[0].getAttribute("data-name");
for (const voice of voices) {
if (voice.name === selectedOption) {
utterThis.voice = voice;
}
}
utterThis.pitch = pitch.value;
utterThis.rate = rate.value;
synth.speak(utterThis);
utterThis.onpause = (event) => {
const char = event.utterance.text.charAt(event.charIndex);
console.log(
`Speech paused at character ${event.charIndex} of "${event.utterance.text}", which is "${char}".`,
);
};
inputTxt.blur();
};
Im letzten Teil des Handlers fügen wir ein pause-Ereignis ein, um zu demonstrieren, wie SpeechSynthesisEvent gut verwendet werden kann. Wenn SpeechSynthesis.pause() aufgerufen wird, wird eine Meldung zurückgegeben, die die Zahl und den Namen des Zeichens angibt, bei dem die Sprache pausiert wurde.
Schließlich rufen wir blur() auf dem eingetippten Text auf. Dies dient hauptsächlich dazu, die Tastatur auf Firefox OS auszublenden.
Aktualisieren der angezeigten Pitch- und Ratewerte
Der letzte Teil des Codes aktualisiert die in der Benutzeroberfläche angezeigten pitch-/rate-Werte, jedes Mal, wenn die Schiebereglerpositionen bewegt werden.
pitch.onchange = () => {
pitchValue.textContent = pitch.value;
};
rate.onchange = () => {
rateValue.textContent = rate.value;
};